hi 大家好,使用 PostgreSQL 開發了一陣子,近期認識了 HSTORE 這個資料型態, 但 HSTORE 跟 JSONB 有什麼不同呢 ?
這篇文章會帶大家認識在 PostgreSQL 中 HSTORE 與 JSONB 的差別。
# Data types - HSTORE
從 sequelize source code 中可以看到 這個資料型態是以 key / value 的方式儲存,相較於資料型態 JSONB 從下方的圖片可以看到 query 的 performance 是相對好一些的。
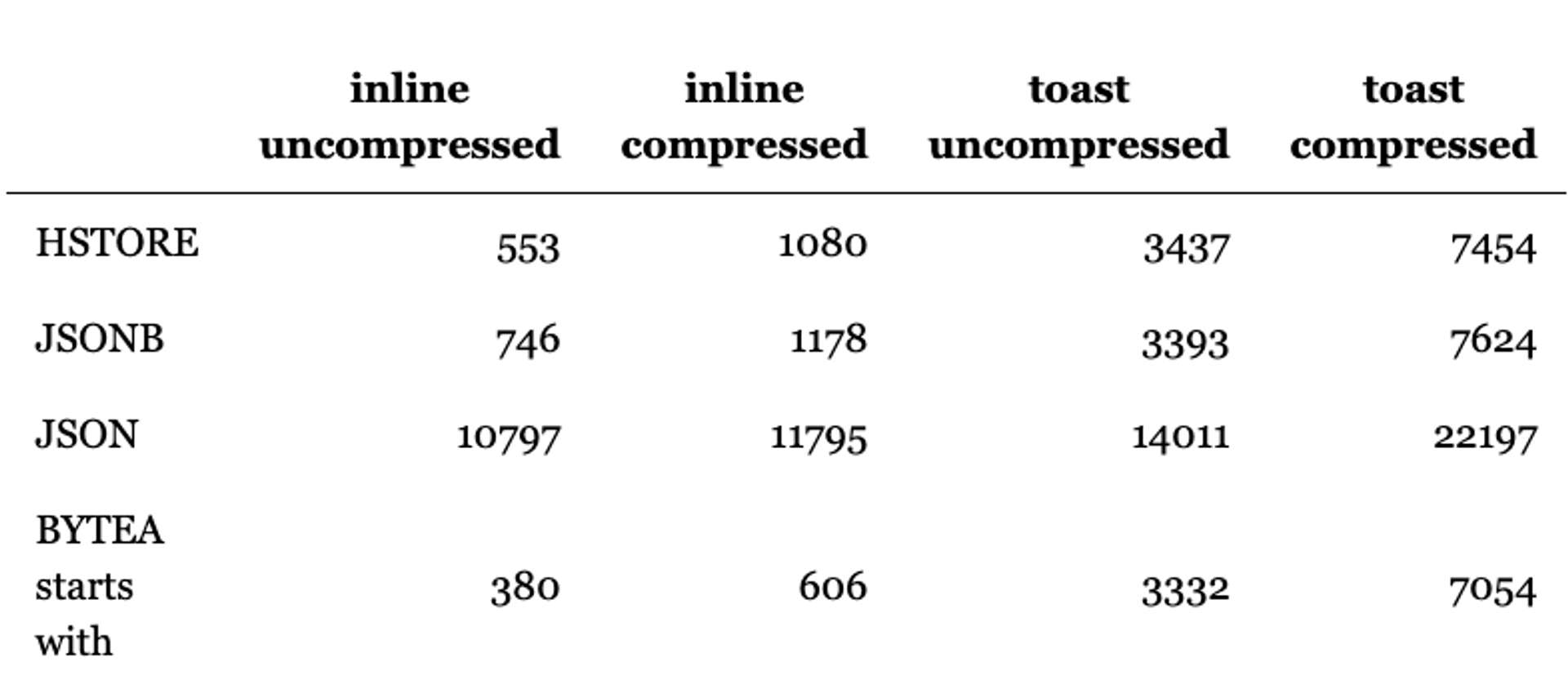
圖片資料來源: Postgres large JSON value query performance
# Data types - JSONB
在實務上處理 json 類型的資料還是會選擇 JSONB 居多,一方面是因為 schemaless ,不需要細部定義 attributes 內有哪些 key / value,二方面是 儲存資料時將 JSON format 成 binary,因此 query 已經相較於一般的 JSON 有效率了。
從下方圖片可以看到 JSONB 資料型態的出現, postgresql 的使用率開始慢慢爬升。
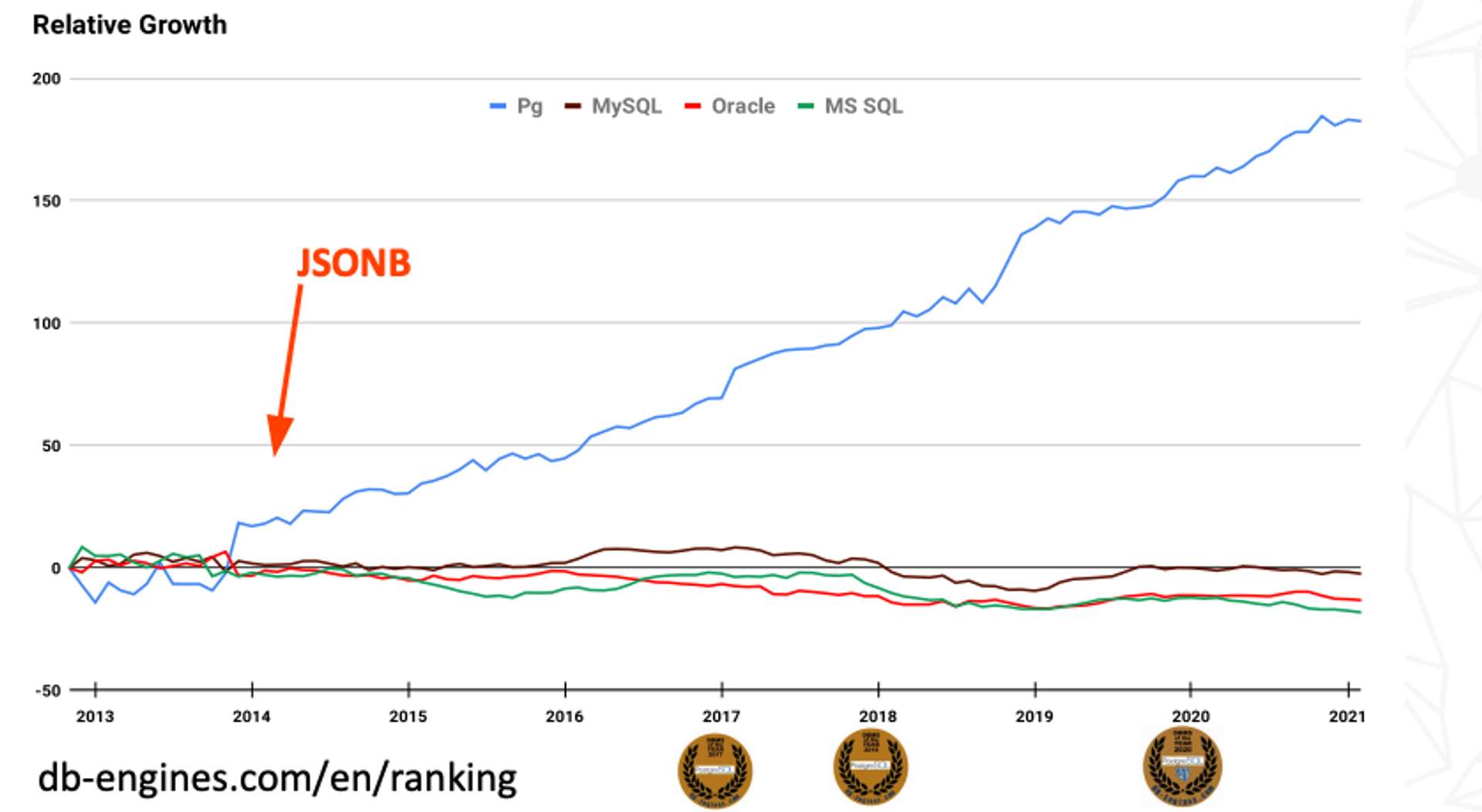
圖片資料來源:Understanding JSONB Performance - PGCONF NYC 2021
# Postgres 背後如何處理與儲存大型的資料呢?
以下為 postgresql 官方文件 上提到的 TOAST infrastructure :
PostgreSQL uses a fixed page size (commonly 8 kB), and does not allow tuples to span multiple pages. Therefore, it is not possible to store very large field values directly. To overcome this limitation, large field values are compressed and/or broken up into multiple physical rows. This happens transparently to the user, with only small impact on most of the backend code. The technique is affectionately known as TOAST (or “the best thing since sliced bread”). The TOAST infrastructure is also used to improve handling of large data values in-memory.
The TOAST management code is triggered only when a row value to be stored in a table is wider than TOAST_TUPLE_THRESHOLD bytes (normally 2 kB).
簡單來說,資料量大於 2 kB 時 資料經由壓縮後會被切分成固定大小的 TOAST chunks (1996B for 8KB page)儲存,從下方圖片可以看到每個 chunk 各自會有自己的 chunk_id。
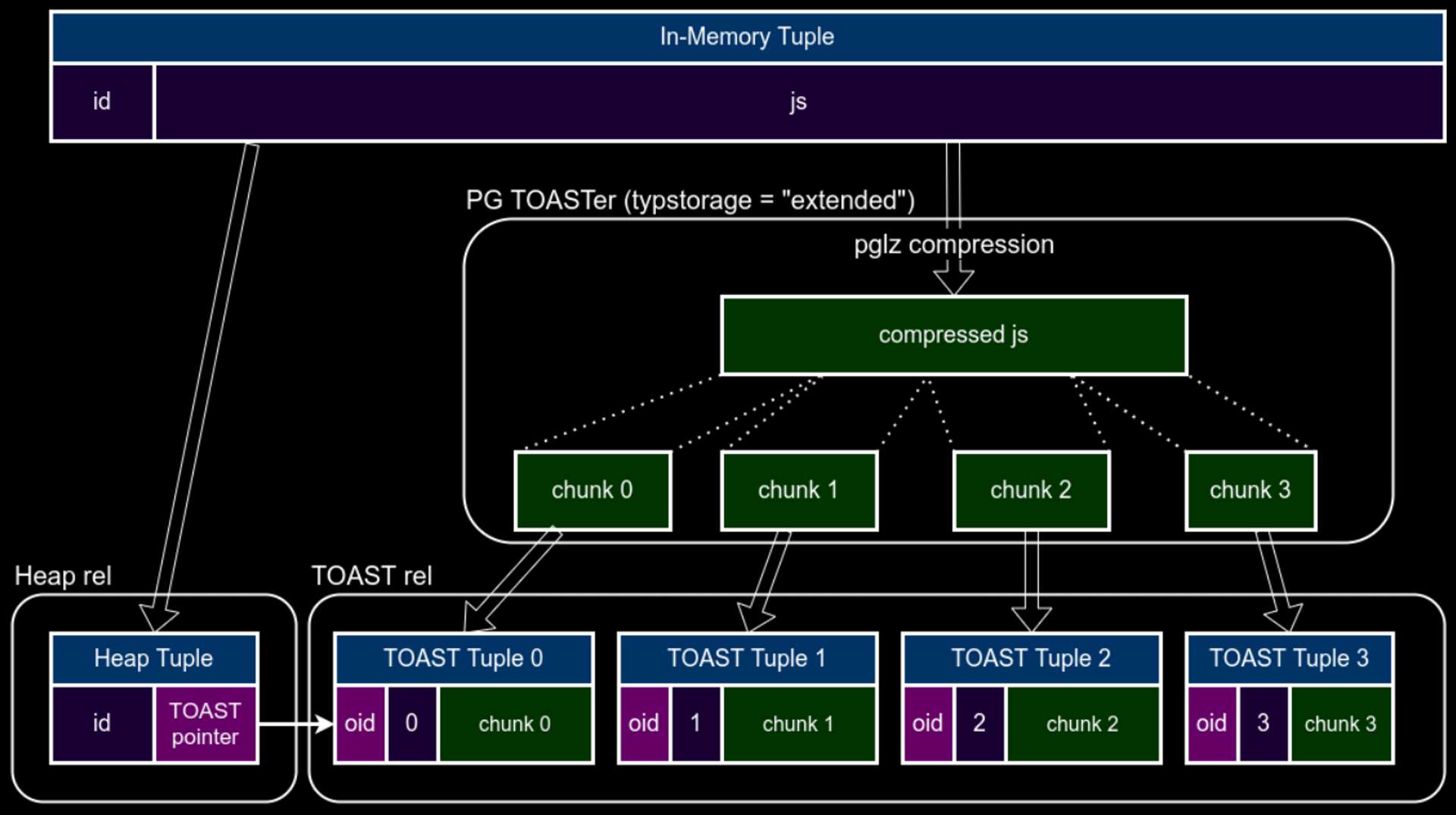
圖片資料來源:Understanding JSONB Performance - PGCONF NYC 2021
# 當 TOAST storage 被觸發時, JSONB 的效能?
When you update a value that's in TOAST, it always duplicates the whole value. That means even if you have a megabyte JSONB document and you're just updating a single part of that, with the correct syntax and whatnot in Postgres, Postgres for these large values has no way to avoid making a full copy of that TOAST value. And it's a problem because of the WAL traffic.
資料來源:Understanding JSONB Performance - PGCONF NYC 2021
簡單來說,在 TOAST 的實作下 JSONB 的效能會不太好。
# 小結
透過了解在不同型態與資料量背後被處理與儲存的方式後,可以更有依據的思考如何定義資料型態。
在閱讀文章時如果有遇到什麼問題,或是有什麼建議,都歡迎留言告訴我,謝謝。😃
# 參考資料
- Documentation | storage-toast
- Blog | Introduction to PostgreSQL physical storage
- Blog | Postgres large JSON value query performance
- Presentation | Understanding JSONB Performance - PGCONF NYC 2021
關於作者
喜歡有趣的設計